How Deep Reinforcement Learning is Sneaking Up on Path Planning and Winning Big Time
Hey there, fellow tech enthusiast! Welcome to our TechBit series by VECROS.
While thinking about the challenges of coordinating autonomous systems in unpredictable environments, much like navigating the complexities of urban traffic or even blockchain consensus, I came across early explorations of reinforcement learning in robotics. It struck me how these methods echoed broader themes in decision-making: balancing rigid rules with adaptive learning. This brings me to a recent survey paper on arXiv, “The Emergence of Deep Reinforcement Learning for Path Planning” by Thanh Thi Nguyen, et.al. This paper[1] synthesizes how deep reinforcement learning (DRL) is transforming path planning in domains like drones and mobile robots, shifting from static algorithms to dynamic, experience-driven strategies. In what follows, I’ll unpack its key insights, drawing parallels to decision theories a some examples to clarify the underlying mechanics.
The Path Planning Puzzle: Why It’s Kinda Like Playing Mario in Real Life
Path planning, at its core, is about finding an optimal trajectory from an initial state to a goal while avoiding obstacles and minimizing costs such as energy or time. Consider it akin to a chess player plotting moves on a board where pieces shift unpredictably: the environment is not a fixed grid but a dynamic space with unknown elements, like moving hazards in a disaster zone or variable objects in the path of a drone.
Traditional methods have long dominated this space, treating the problem as a search over a graph or an optimization puzzle. But as environments grow more complex, high-dimensional state spaces, partial observability these approaches reveal their limitations. The survey positions DRL as an emergent alternative, where agents learn policies through interaction, much like how humans refine strategies via trial and error rather than exhaustive computation.
Start position: Agent at (0,0), Goal at (5,5)
Obstacles at (2,2), (3,4)
Possible moves: Up, Down, Left, Right
Traditional graph search: Build nodes, edges; apply A* to minimize distance.
The Old School Ways: Graphs, Math, and a Dash of Evolution
Before delving into DRL, it’s worth crystallizing the “old school” techniques, as the paper does. Graph-based methods, such as A*, model the environment as nodes (positions) and edges (actions), using heuristics to guide searches efficiently. Linear programming frames paths as constrained optimizations, solving for variables like velocity under bounds. Evolutionary algorithms, meanwhile, simulate natural selection: generate populations of paths, mutate them, and select fittest survivors based on fitness functions.
These are robust in structured, known settings, think a warehouse with fixed shelves. Yet, they embody a “data-driven” rigidity: reliant on complete models, they struggle with scalability in dynamic or high-dimensional scenarios. Imagine optimizing a supply chain with perfect information versus one disrupted by real-time events; the former excels, the latter exposes brittleness. The survey critiques this as akin to ideological dogmas in philosophy: useful simplifications, but prone to failure when contexts evolve beyond their assumptions.
The Rise of DRL: Learning by Bumping Into Walls (Literally)
DRL reframes path planning within a Markov Decision Process (MDP): an agent observes states (e.g., position, sensor data), selects actions from a policy, receives rewards (positive for progress, negative for collisions), and transitions to new states. The “deep” aspect integrates neural networks to approximate value functions or policies in vast state spaces. This is less about precomputing paths and more about learning a generator of behaviors. Reward functions act as principles: dense rewards guide quick learning, sparse ones mimic long-term goals but risk inefficiency.

Key algorithms highlighted include:
-
Double DQN: Mitigates overestimation biases, applied to UAV data collection where paths must adapt without overvaluing risky moves.
-
Optimized Q-Learning: Enhances local planning for mobile robots, refining actions in real-time.
-
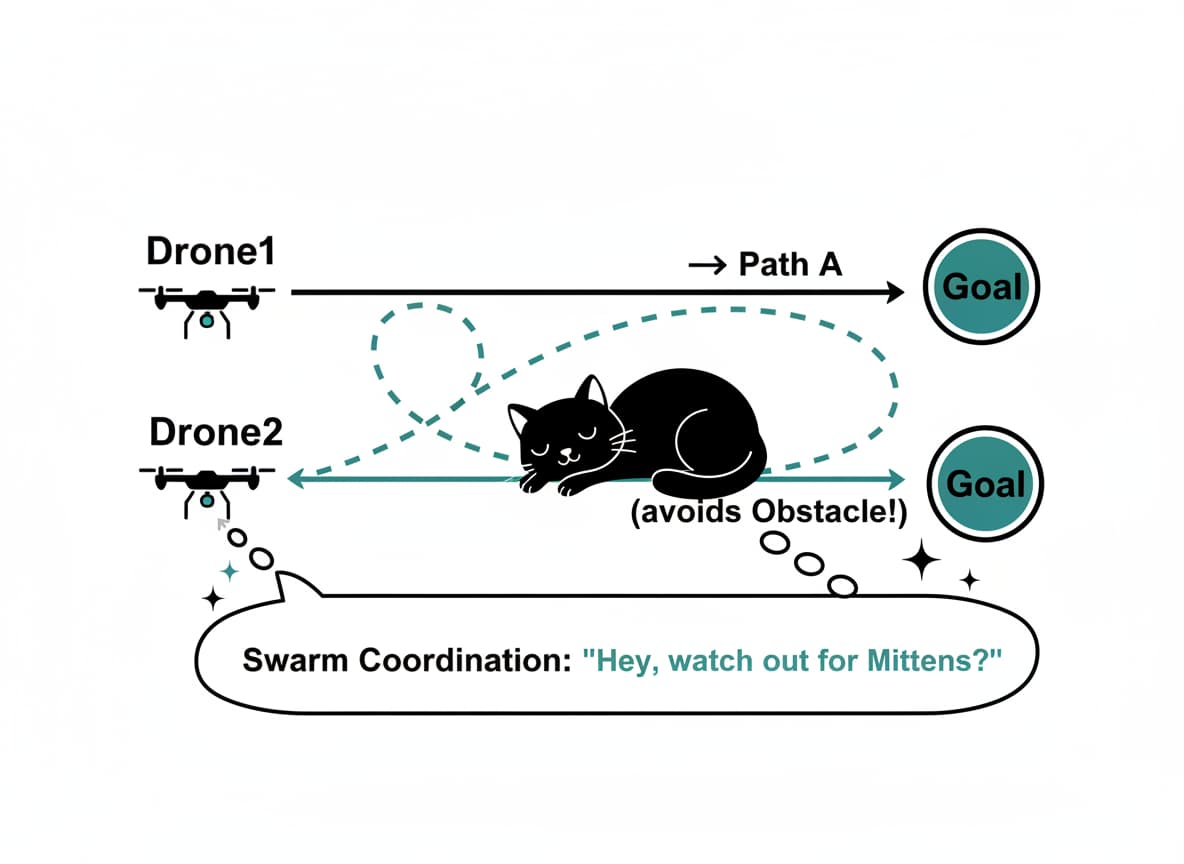
Multi-Agent RL: Coordinates swarms, decomposing tasks like a company aligning departments toward shared objectives.
the loop is iterative:
Observe States
Select Action a ~ π(θ) // Policy parameterized by neural net θ
Execute a → New State s’, Reward r
Update: θ ← θ + α * ∇(Q(s,a) - (r + γ max Q(s’,a’)))
This feedback refines the policy, fostering adaptability where traditional methods would recompute from scratch.
Real-World Wins: Drones Delivering, Robots Rescuing
The paper surveys DRL’s triumphs in real-world domains. For drones (UAVs), it enables efficient data harvesting or delivery, optimizing flights amid obstacles like trees or crowds. In robotics, search-and-rescue agents prioritize high-probability areas, adapting to environmental drifts.
Multi-agent scenarios shine: swarms avoid collisions while task-sharing, evoking social coordination theories. DRL’s edge lies in handling uncertainty, partial maps, sensor noise making autonomy viable in chaotic settings, from disaster response to urban logistics.

The Bumps in the Road: Challenges (Because Nothing’s Perfect)
Yet, DRL is not without flaws, mirroring critiques of overly abstract philosophies. Training demands vast data and computation; sparse rewards lead to slow convergence, like searching for principles in a haystack. Real-world transfer from simulations remains tricky! simulated physics rarely match reality’s noise or faults.
Safety is paramount: learned policies may exploit shortcuts, risking collisions in high-stakes environments. The survey echoes broader concerns in AI: explainability lags behind traditional methods, which offer traceable logic.
Future Paths: Hybrid Heroes and Adaptive Adventures
Synthesizing these, the paper advocates hybrids: blend DRL’s adaptability with classical reliability, perhaps using heuristics to bootstrap learning or human oversight for safety. Future directions include better sim-to-real bridges and evolving policies that self-improve mid-deployment.
In short, this could represent a synthesis: data-driven empiricism selecting among idea-driven learning paradigms. Speculatively, within a decade, DRL hybrids might underpin everyday autonomy, from drones to self-driving fleets, evolving as environments do much like how ideologies adapt in resilient societies. The survey invites us to view path planning not just as engineering, but as a microcosm of intelligent decision-making.
TL;DR: The Quick Scoop
Here’s a fun table comparing traditional vs. DRL path planning:
| Aspect | Traditional Methods | DRL Vibes |
|---|---|---|
| Strengths | Fast in simple maps, explainable | Adaptive, handles chaos |
| Weaknesses | Rigid, scales poorly | Compute-hungry, black-box |
| Best For | Structured worlds | Drones in wild unknowns |
| Fun Factor | Predictable puzzles | Learning adventures! |
[1] Reference : The Emergence of Deep Reinforcement Learning for Path Planning
If this sparked your curiosity, do comment and share ![]()
Footnotes ↩︎